Step-by-Step Guides출처: DigitalOcean조회수 33
Build an End-to-End RAG Pipeline for LLM Applications
By Shaoni Mukherjee2026년 3월 19일
**Build an End-to-End RAG Pipeline for LLM Applications**
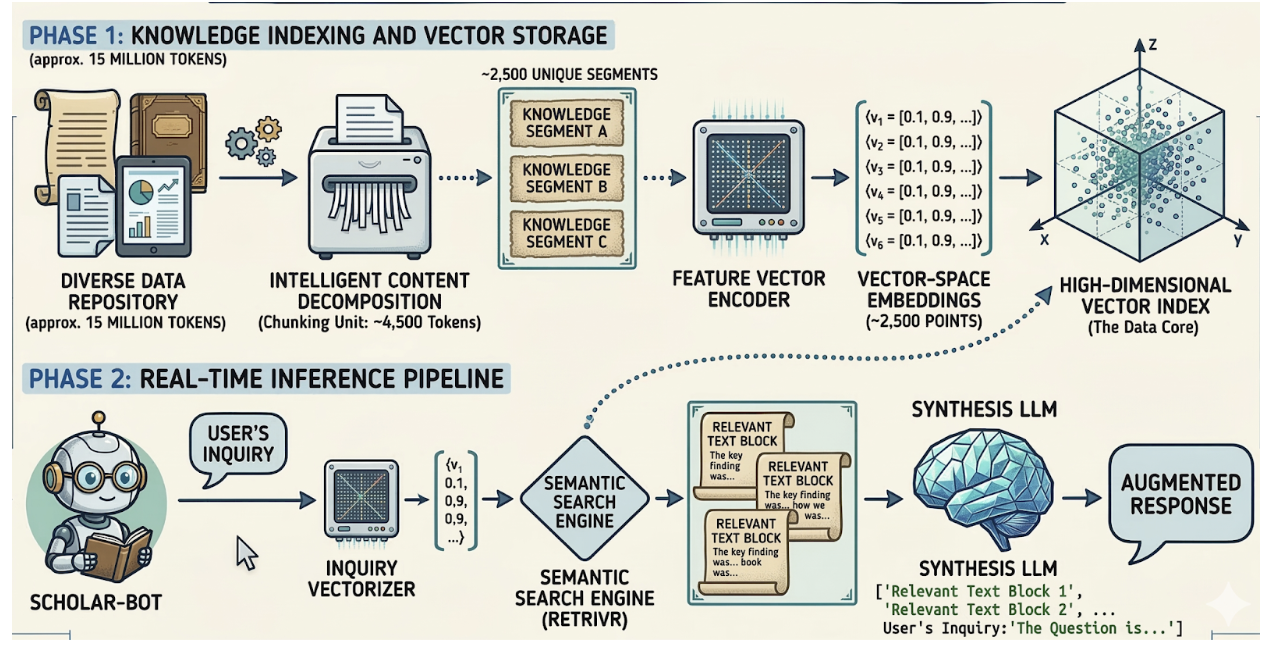
Large language models have transformed the way we build intelligent applications. Generative AI Models can summarize documents, generate code, and answer complex questions. However, they still face a major limitation: they cannot access private or continuously changing knowledge unless that information is incorporated into their training data. Retrieval-Augmented Generation (RAG) addresses this limitation by combining information retrieval systems with generative AI models. Instead of relying entirely on the knowledge embedded in model weights, a RAG system retrieves relevant information from external sources and provides it to the language model during inference...
---
**[devsupporter 해설]**
이 기사는 DigitalOcean에서 제공하는 최신 개발 동향입니다. 관련 도구나 기술에 대해 더 알아보시려면 원본 링크를 참고하세요.
Large language models have transformed the way we build intelligent applications. Generative AI Models can summarize documents, generate code, and answer complex questions. However, they still face a major limitation: they cannot access private or continuously changing knowledge unless that information is incorporated into their training data. Retrieval-Augmented Generation (RAG) addresses this limitation by combining information retrieval systems with generative AI models. Instead of relying entirely on the knowledge embedded in model weights, a RAG system retrieves relevant information from external sources and provides it to the language model during inference...
---
**[devsupporter 해설]**
이 기사는 DigitalOcean에서 제공하는 최신 개발 동향입니다. 관련 도구나 기술에 대해 더 알아보시려면 원본 링크를 참고하세요.