Latest Trends출처: Netflix Tech조회수 97
MediaFM: The Multimodal AI Foundation for Media Understanding at Netflix
By Netflix Technology Blog2026년 2월 24일
**MediaFM: The Multimodal AI Foundation for Media Understanding at Netflix**
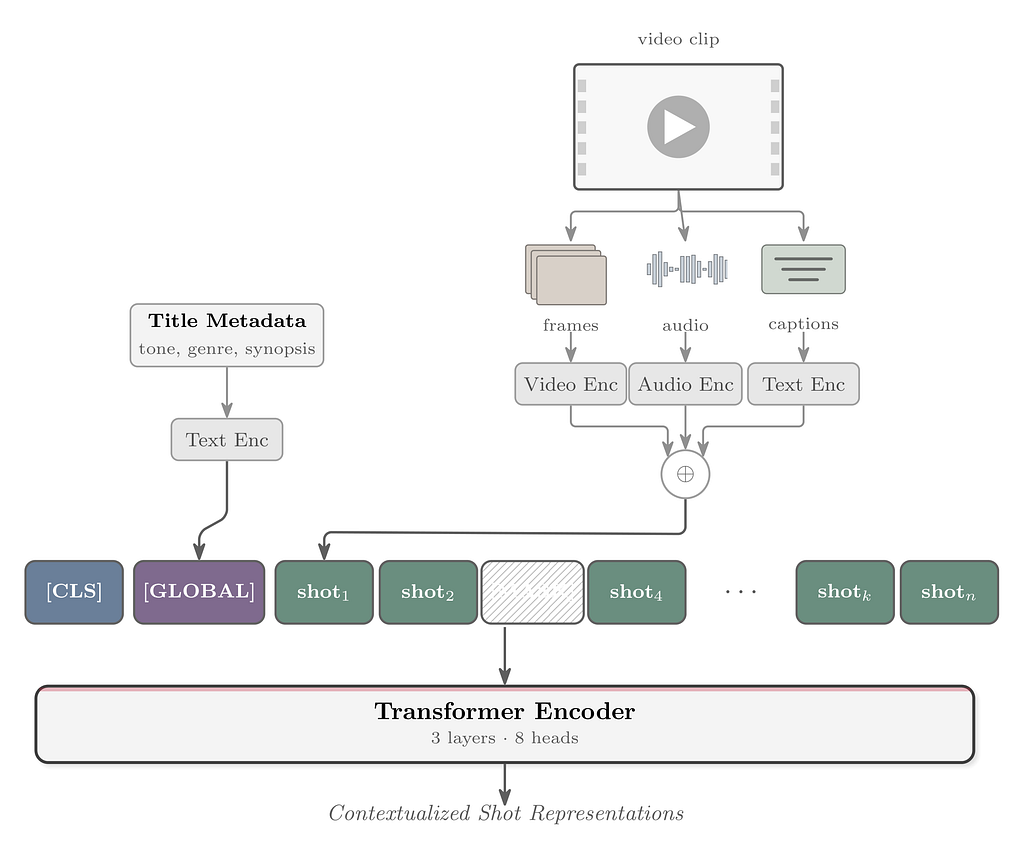
Avneesh Saluja, Santiago Castro, Bowei Yan, Ashish RastogiIntroductionNetflix’s core mission is to connect millions of members around the world with stories they’ll love. This requires not just an incredible catalog, but also a deep, machine-level understanding of every piece of content in that catalog, from the biggest blockbusters to the most niche documentaries. As we onboard new types of content such as live events and podcasts, the need to scalably understand these nuances becomes even more critical to our productions and member-facing experiences.Many of these media-related tasks require sophisticated long-form video understanding e.g., identifying subtle narrative dependencies and emotional arcs that span entire episodes or films. Previous work has found that to truly grasp the content’s essence, our models must leverage the full multimodal signal. For example, the audio soundtrack is a crucial, non-visual modality that can help more precisely identify clip-level tones or when a new scene starts...
---
**[devsupporter 해설]**
이 기사는 Netflix Tech에서 제공하는 최신 개발 동향입니다. 관련 도구나 기술에 대해 더 알아보시려면 원본 링크를 참고하세요.
Avneesh Saluja, Santiago Castro, Bowei Yan, Ashish RastogiIntroductionNetflix’s core mission is to connect millions of members around the world with stories they’ll love. This requires not just an incredible catalog, but also a deep, machine-level understanding of every piece of content in that catalog, from the biggest blockbusters to the most niche documentaries. As we onboard new types of content such as live events and podcasts, the need to scalably understand these nuances becomes even more critical to our productions and member-facing experiences.Many of these media-related tasks require sophisticated long-form video understanding e.g., identifying subtle narrative dependencies and emotional arcs that span entire episodes or films. Previous work has found that to truly grasp the content’s essence, our models must leverage the full multimodal signal. For example, the audio soundtrack is a crucial, non-visual modality that can help more precisely identify clip-level tones or when a new scene starts...
---
**[devsupporter 해설]**
이 기사는 Netflix Tech에서 제공하는 최신 개발 동향입니다. 관련 도구나 기술에 대해 더 알아보시려면 원본 링크를 참고하세요.